Parallelization policy
GKX parallelization claims are separated by workload class and by the identity gates that currently exist. Treat this page as the short policy; the long artifact history remains in Performance and runnable examples remain in Examples.
For release notes and manuscripts, read this page together with Release Scope and Claim Boundaries. Independent scans and ensembles are the current production path. Whole-state nonlinear sharding and nonlinear domain or velocity-space decomposition remain diagnostic correctness/profiler paths until they pass workload-specific identity, conservation, transport-window, and matched profiler gates.
Strategy registry
The metadata API exposes a JSON-friendly strategy table. Release-ready
independent-work rows are intentionally ordered first: independent_ky_scan,
then uq_ensemble.
|
|
|
|
|---|---|---|---|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
|
Production path: independent work
Production-ready parallelism is currently scoped to independent solver calls:
independent
k_yscans;quasilinear calibration grids;
finite-difference and sensitivity batches;
UQ and ensemble workloads.
Use gkx.ky_scan_batches and gkx.batch_map for JAX-array
workloads, and gkx.independent_map for file-backed Python tasks.
These helpers preserve serial ordering and restrict communication to result
aggregation. Any timing claim from this path must be paired with a serial
numerical-identity gate for the reported observables, such as gamma,
omega, quasilinear weights, or covariance summaries.
For UQ and optimization portfolios, gkx.independent_ensemble_provenance_gate
is the compact production-readiness check. It runs the same member function
serially and through independent_map, verifies numerical identity and result
ordering, checks that oversubscribed worker requests clip to the ensemble size,
reconstructs the deterministic independent-work decomposition, and probes
IndependentMapExecutionError metadata for worker failures. This is a
provenance and identity gate only; it does not make a nonlinear
domain-decomposition speedup claim.
Runtime k_y scans can request the same independent-worker policy directly
from TOML. This is a scan orchestration path, not a solver-layout sharding path:
[parallel]
strategy = "batch"
axis = "ky"
num_devices = 4 # or batch_size = 4
backend = "auto" # "thread" or "process" are explicit alternatives
When command-line scan workers are not set explicitly, strategy = "batch"
with axis = "ky" resolves to independent per-k_y solver calls and
records the resolved worker policy in runtime scan artifacts.
The large tracked artifacts use real solver work rather than synthetic sleeps:
docs/_static/independent_ky_scan_scaling_large.json covers Cyclone linear
k_y scans, and docs/_static/quasilinear_uq_ensemble_scaling_large.json
covers a late-time linear/quasilinear UQ ensemble. These are the figures to cite
for current parallelization speedup claims.
Production closure status
The release status artifact combines the production scaling evidence and the diagnostic decomposition gates into one machine-readable claim boundary:
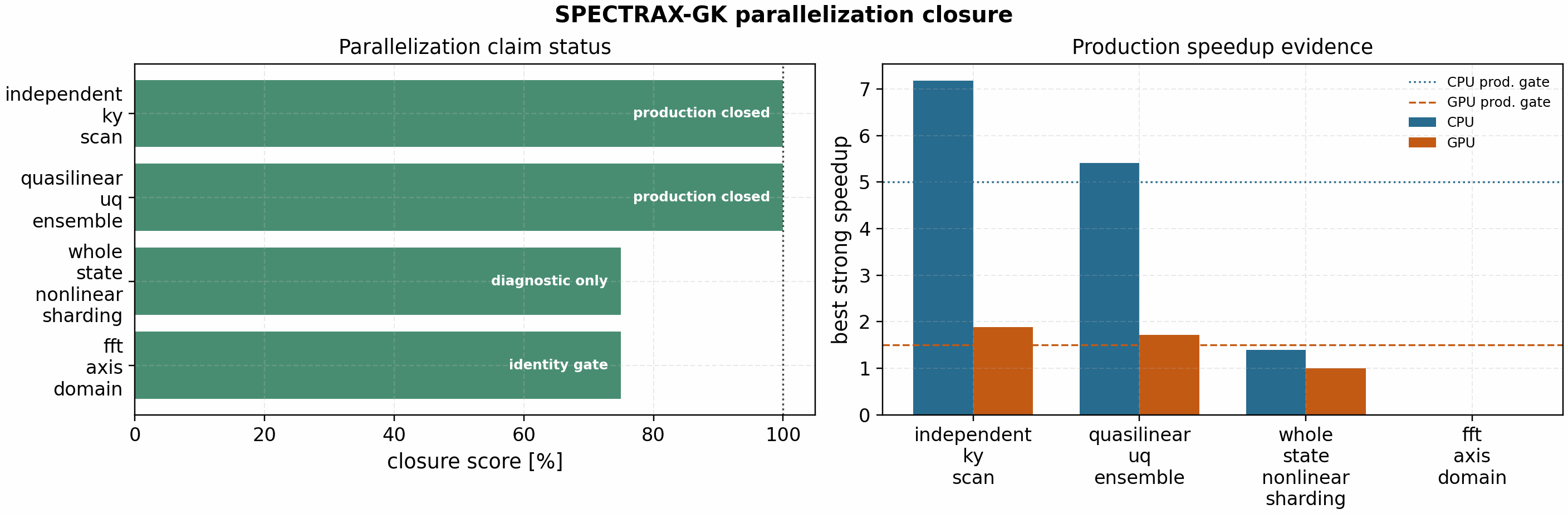
docs/_static/parallelization_completion_status.json reports the release
production-completion percentage and the status of each lane. For the current
tracked artifacts, production independent-work parallelization is closed:
independent k_y scans reach 7.18x on eight CPU workers and 1.88x on
two RTX A4000 GPUs, while the quasilinear/UQ ensemble reaches 5.41x on CPU
and 1.71x on GPU. The same status now embeds the independent
UQ/optimization provenance gate for serial-vs-parallel ordering, worker
clipping, exception metadata, and deterministic reconstruction. Whole-state
nonlinear sharding and FFT-axis decomposition remain diagnostic, not production
nonlinear speedup claims.
The lower-level decomposition-contract status checks deterministic shard assignment, serial reconstruction identity, and claim-level separation without rerunning large profiles.
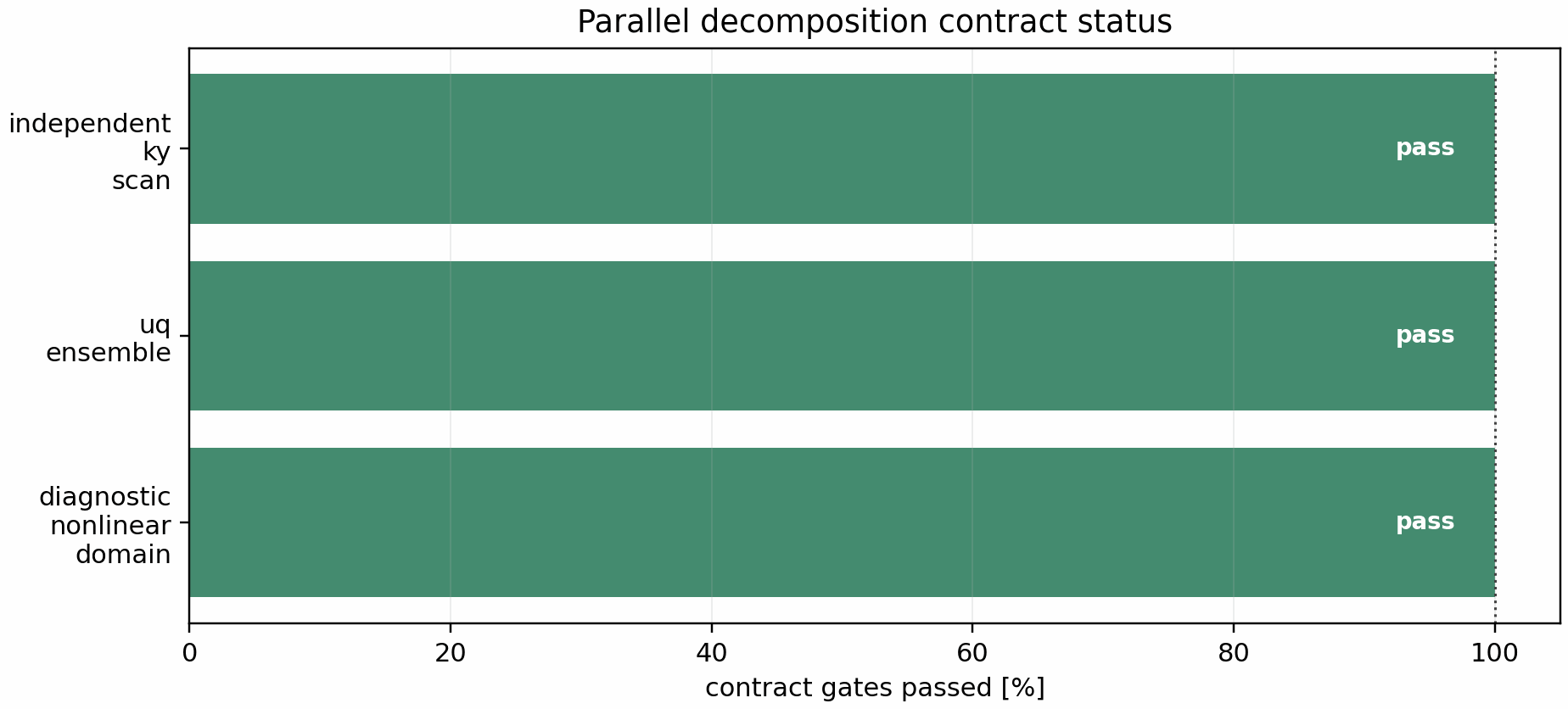
This status passes for production independent k_y and UQ portfolios and
for a diagnostic nonlinear state-domain partition. Passing the diagnostic row
does not imply runtime nonlinear domain decomposition: it only proves that the
metadata split/reassemble contract is internally consistent and correctly
scoped as non-production.
Diagnostic path: whole-state nonlinear sharding
Fixed-step whole-state nonlinear sharding is diagnostic-only. The
integrate_nonlinear_sharded / TimeConfig.state_sharding path is useful
for control-flow validation, state-axis identity gates, profiler localization,
and testing candidate layouts. It is not a production nonlinear domain
decomposition or multi-GPU speedup claim. Do not use it as evidence for a
whole-state nonlinear sharding speedup; it has no scoped speedup claim until
separate identity gates and matched profiler artifacts exist for that exact
workload.
In particular, current whole-state sharding does not close the communication
problem for nonlinear FFTs, halo exchange, conservation checks, or benchmark-size
transport runs. z-axis FFT sharding is not release-gated until it has a
separate communication/layout design and a passing identity gate.
The large CPU/GPU sweep in
docs/_static/nonlinear_sharding_strong_scaling_large.json confirms the
policy: the final state is identity-correct, but logical-CPU speedup saturates
near 1.39x and the June 21, 2026 two-RTX-A4000 auto route is slower
than one GPU for the tracked larger fixed-step case (0.586x strong
scaling). That artifact is therefore valuable engineering evidence, not a
production nonlinear speedup result.
The combined artifact is intentionally fail-closed: identity_passed may be
true while speedup_passed is false, with explicit speedup_blockers naming
the backend/device row that regressed.
The companion gate
docs/_static/nonlinear_sharding_production_speedup_gate.json is the only
artifact that may promote whole-state nonlinear sharding wording beyond
diagnostic/profiler evidence, and only for the exact workload it gates. The fast
checker
tools/release/check_parallel_scaling_artifacts.py now validates that gate, its CSV
sidecar, its CPU/GPU source rows, its required-backend blockers, and the
per-backend blocker report without rerunning long CPU or GPU profilers. The
report keeps identity-evidence blockers separate from speedup/efficiency
blockers so an identity-complete slowdown remains diagnostic rather than a
production speedup claim.
The next decomposition step is also gated, but still diagnostic. The artifact
docs/_static/nonlinear_domain_parallel_identity_gate.json exercises a
deterministic local nonlinear state update with one-cell halo chunks and checks
the decomposed result against the serial update before enabling that prototype
path. This validates the fail-closed identity-gate contract for a bounded local
stencil. The report records the gate name, plan-validity status, and any
explicit blocker reasons such as noncanonical axes, incomplete chunk coverage,
or serial/decomposed shape mismatches; any blocker disables the decomposed
prototype path even if the arrays being compared are numerically equal. The
same JSON now embeds a stricter transport-window sub-gate,
nonlinear_domain_transport_window_identity, that advances the serial and
halo-decomposed prototypes over a short fixed-step window and compares final
state identity, boundary identity, mass-trace identity, free-energy-proxy trace
identity, and boundary-flux-proxy trace identity. The drift values in that
sub-gate are serial-vs-decomposed agreement checks for the damped diagnostic
stencil; they are not production conservation claims. The artifact still does
not validate distributed FFTs, field solves, runtime routing, benchmark
transport acceptance, or speedup.
The spectral communication layer now has the same fail-closed treatment. The
artifact docs/_static/nonlinear_spectral_communication_identity_gate.json
uses deterministic complex spectral coefficients in (N_l,N_m,N_y,N_x,N_z)
layout and now combines five diagnostic layers in one JSON sidecar. First, it
applies the split/reassemble and axis-transpose operations that a distributed
FFT route would need and compares FFT round-trip, pseudo-spectral bracket, and
spectral field-solve layout. Second, it owns row-major logical (k_y,k_x)
tiles, reconstructs them, recomputes the spectral field and bracket, and gates
the serial nonlinear RHS contribution -\{\phi,g\} against the
tile-reassembled route. Third, it advances a short fixed-step micro-integration
and checks final-state, free-energy-proxy, field-energy-proxy, and flux-proxy
trace identity. Fourth, it exercises a pencil-FFT fused-bracket route that
stacks the derivative operands, performs explicit axis-wise FFT stages, and
returns the RHS without reconstructing logical output tiles. Fifth, it advances
the same pencil route over a short physical-space transport window and compares
final state, free-energy, field-energy, bracket-RMS, and
density-times-radial-electric-field transport-proxy traces. Passing this
combined gate promotes fft_axis_domain from blocked to diagnostic. It still
does not add device-level pjit/shard_map distributed FFT routing,
benchmark nonlinear conservation checks, accepted turbulent transport-window
physics, or any speedup claim.
The package also exposes
gkx.operators.nonlinear.parallel.nonlinear_spectral_rhs_identity_gate,
gkx.operators.nonlinear.parallel.logical_decomposed_nonlinear_spectral_rhs,
and gkx.operators.nonlinear.parallel.nonlinear_spectral_integrator_identity_gate
for focused tests. They are useful because they exercise field/bracket/RHS and
fixed-step dataflow instead of only layout round trips. They remain fail-closed
and diagnostic-only: logical tiles are reconstructed for identity validation,
not executed through a production pjit/shard_map distributed FFT path.
The routed spectral-domain timing artifact
docs/_static/nonlinear_spectral_domain_routing_profile.json makes that
claim boundary quantitative. The current logical route is identity-clean, but
its global-reconstruction work model gives a communication/owned-work ratio
6.375 and a parallel-efficiency ceiling 0.136 for the tracked
(N_l,N_m,N_y,N_x,N_z)=(2,4,32,32,4) four-tile profile. The pencil route
removes the global reconstruction from the model and gives a
communication/FFT-work ratio 0.075 with an efficiency ceiling 0.930.
That is only a plausibility screen: the tracked local CPU timing still fails
the speedup gate, with the logical route at about 1.08x and the current
pencil staging at about 0.75x relative to the serial JIT route. The next
production step is therefore device-level pencil-FFT routing with real
collectives and profiler evidence, not a speedup claim from the local
axis-staged diagnostic.
The first real-device candidate is a z-sharded fused pencil RHS, produced
with tools/profiling/profile_device_z_pencil_transport_window.py --mode rhs.
This route
keeps the FFT axes local on each device, shards the field-line dimension, and
avoids global spectral tile reconstruction. The tracked logical-CPU artifact
docs/_static/nonlinear_device_z_pencil_rhs_cpu4_profile.json confirms
serial-vs-sharded RHS identity on two and four CPU devices for a
(4,16,96,96,32) nonlinear bracket workload, with maximum absolute RHS error
7.6e-10. The shard_map route is a CPU RHS speedup candidate on this
machine (1.51x on two logical CPU devices and 2.62x on four). The
matching two-GPU office artifact
docs/_static/nonlinear_device_z_pencil_rhs_gpu2_profile.json is also
identity-clean after host staging the initial state before applying explicit z
sharding (max_abs_error=5.24e-10), but the two-GPU timing is only 1.09x
of the single-GPU serial JIT route. These artifacts therefore support a
CPU-microkernel speedup candidate, not a production nonlinear
domain-decomposition claim.
The physical transport-window follow-up is tracked separately. The CPU profile
docs/_static/nonlinear_device_z_pencil_transport_cpu4_profile.json advances
the same serial and z-sharded routes for four fixed nonlinear steps and checks
the final state plus free-energy, field-energy, physical-flux, and bracket-RMS
traces. It passes the active identity gates and reaches 1.61x on two
logical CPU devices and 3.13x on four. The two-GPU profile
docs/_static/nonlinear_device_z_pencil_transport_gpu2_profile.json also
passes transport-window identity, with maximum final-state absolute error
7.45e-9, but reaches only 1.48x and remains below the 1.5x speedup
gate. The profiler artifacts include HLO keyword summaries and Perfetto trace
locations; both CPU and GPU sharded HLO summaries show local FFTs and no
all-to-all or collective-permute operations. The remaining nonlinear
parallelization blocker is therefore production workload granularity and
end-to-end solver routing, not this micro-route’s serial-vs-sharded identity.
For larger diagnostic grids, tools/profiling/profile_device_z_pencil_transport_window.py
also accepts --z-chunk-size and --auto-z-chunk-size. The automatic
mode uses the device-z pencil FFT batch-pressure model to keep the largest
axis-wise cuFFT batch below a configured cap before timing. Combined with
XLA_PYTHON_CLIENT_PREALLOCATE=false on office GPUs, the chunked route avoids
the cuFFT plan failures seen on the unchunked 96x96x64 and 128x128x32
transport windows, but the measured two-GPU speedups remain below the 1.5x
promotion gate.
Add --observable-repeats to the same profiler when deciding whether the
next optimization target is the sharded compute route or the scalar
diagnostic/host-gather path. The timed speedup row remains compute-only; the
observable_gate_* fields are a separate bottleneck split and do not promote
nonlinear domain decomposition by themselves.
The companion --observable-mode sharded_reduce option computes those scalar
observables through device-side z reductions and is useful for identity
debugging. It is not a production mode by itself because the current
implementation recomputes the nonlinear bracket for diagnostics; the production
target is a fused RHS/update path that accumulates the scalar diagnostics while
the bracket is already available.
The tracked two-GPU split artifact
docs/_static/nonlinear_device_z_pencil_transport_gpu2_observable_split_profile.json
passes identity on the auto-chunked 96x96x64 diagnostic, but still records
only 1.19x compute speedup and a large observable-gate overhead. This keeps
the nonlinear decomposition lane diagnostic until an end-to-end solver route
passes identity and speedup with streamed diagnostics.
Before nonlinear domain decomposition can be promoted beyond this diagnostic state, the runtime route must pass all of the following gates on the same workload family that appears in the speedup figure:
full nonlinear RHS identity for
dG,phi, the nonlinear bracket, density/field-solve layout, Hermitian projection, and dealiasing;fixed-step serial-vs-decomposed integration identity for final state, final fields, final RHS, and per-step scalar traces;
boundary/interface identity for owned and halo cells, not only a global norm;
conservation agreement for density/mass, a free-energy-like diagnostic, zonal response, and heat-flux proxies;
post-transient transport-window agreement for Cyclone, KBM, and at least one stellarator smoke case;
CPU serial, CPU decomposed, one-GPU serial, and two-GPU decomposed parity under the same observable contract;
matched profiler artifacts for the exact backend, device count, software stack, grid, warmups/repeats, and identity tolerance being claimed.
Until those gates exist, nonlinear decomposition work can be documented as diagnostic engineering evidence only, even if a new profile shows positive timing on one machine.
Velocity-space communication gates
Velocity-space decomposition is gated from the bottom up. The accepted planning contract is species-first and Hermite-second, with explicit communication flags for field reductions/broadcasts and Hermite ghost exchange. Each added runtime path must preserve those contracts before being used for performance claims.
The currently gated communication and call-graph layers are:
species/Hermite velocity-sharding planner metadata;
nearest-neighbor Hermite ghost exchange;
Hermite-sharded field reduction and electrostatic field reduction;
species-sharded kinetic-electron quasineutrality reduction;
Hermite streaming-ladder coefficients;
periodic streaming microkernel and streaming-only linear-RHS call graph;
electrostatic streaming, drift-slice, diamagnetic-drive, and composed single-species periodic electrostatic linear-slices gates.
a four-device
2 species x 2 Hermiteperiodic electrostatic streaming RHS gate with species field reductions and Hermite-neighbor exchange.
The opt-in species route now executes the complete electrostatic linear-slice
RHS with one species per device. It performs the shared quasineutrality
collective first, then evaluates streaming, mirror, curvature, grad-B, and
diamagnetic terms on local species shards without reconstructing the global
distribution. For a two-species explicit linear integration, pass
RuntimeParallelConfig(strategy="velocity", axis="species", num_devices=2).
The serial and two-device RHS are identity-gated. The enclosing explicit
pmap also supports the built-in conserving Lenard–Bernstein/Dougherty-like
collision contribution with independent species rates and the high-mode
Hermite/Laguerre hypercollision operator. Nonzero collision-only and populated
high-moment three-step CPU/GPU gates match serial. The standalone shard_map RHS keeps
collisions fail-closed because JAX 0.6.2 cannot reconcile its conditional VMA
annotations. The enclosing pmap also uses the production electromagnetic
field equations: density, parallel-current, polarization, and perpendicular-
pressure moments are reduced with lax.psum before local RHS assembly. A
nonzero-\(A_\parallel\), nonzero-\(B_\parallel\) three-step trajectory
is identity-gated against serial integration. A broad speedup claim remains out
of scope until matched artifacts pass their own gates.
On the office JAX 0.6.2/CUDA stack, device-to-device resharding of an existing
single-GPU array did not preserve the second device’s input. The production
integrator therefore stages species-dependent state/cache arrays from host
memory exactly once, then encloses the complete explicit time loop in a
species-axis pmap. Quasineutrality uses lax.psum; all remaining terms
stay local to their species. A three-step two-A4000 gate agrees with serial
final state to 4.61e-8 relative and field history to 1.59e-9 relative.
Euler, RK2, and sampled field histories are gated; IMEX remains fail-closed.
The fixed-step route also preserves reverse-mode differentiation through the
compiled species pmap. A physical two-species gate differentiates a fixed
linear projection of the evolved ion mode with respect to
\(R/L_{T_i}\) and agrees with a centered finite difference to one percent
in float32. Host staging happens before the differentiated trajectory; traced
parameters are never converted through NumPy. This is a derivative-identity
contract for the explicit electrostatic route, not a claim for adaptive
controllers, IMEX, electromagnetic parameter derivatives, or device
initialization.
The medium grid remains overhead-limited, while a 68 MiB large state passes
identity and reaches a scoped 1.16x two-GPU warm-RHS speedup. This
establishes a workload crossover, not general strong scaling or an end-to-end
GPU integration-speedup claim.
The mixed species–Hermite route partitions both kinetic species and Hermite
moments. Request
backend="electrostatic_species_hermite" with
axis="species_hermite" and four devices to evaluate the periodic,
collision-free electrostatic two-species RHS on a (species, m)=(2,2) mesh.
Quasineutrality
reduces density over both mesh axes, polarization over species only, and the
Hermite ladder exchanges one boundary moment within each species row. Width-one
and width-two exchanges also apply the production mirror, curvature, and
grad-\(B\) equations; global Hermite indices place the diamagnetic drive at
the correct moments. Global basis indices also preserve the physical
normalization of constant and \(|k_z|\) hypercollisions, while perpendicular
hyperdiffusion and end damping remain shard-local. Isolated term gates are
required to be nonzero and match the serial production equations; combined
dissipative Euler/RK2 trajectories pass state and field identity on four
logical CPUs. The factorized conserving collision operator separately reduces
the \(m=0,1,2\) density, momentum, and temperature moments over each
species row; unequal nonzero ion/electron rates and the complete electrostatic
trajectory match serial. The revision-pinned profile covers the core operator
without optional dissipation or collisions and
records 3.11x warm-RHS speedup and exact 100-step state/field identity, but
only 0.97x end-to-end throughput. The route is therefore promoted for
equation ownership and RHS acceleration, not complete integration speedup.
Linked flux-tube boundaries use the same production chain FFT independently on
each shard because ky, kx, and z remain local. A nontrivial linked
case passes combined streaming, linked \(|k_z|\) hypercollision, linked end
damping, conserving collisions, and two-step state/field identity. Mixed-mesh
electromagnetic fields, other integrators, and all GPU claims remain
fail-closed. The office host has only two GPUs, so no four-device mixed-mesh GPU
claim can be tested there.
These gates validate communication and numerical identity for the stated bounded linear paths. They do not validate mixed-mesh electromagnetic fields, multi-species nonlinear field solves, nonlinear brackets, or nonlinear transport speedup unless those paths have their own identity gates and profiler artifacts.
Claim rules
Use the following rules when writing docs, release notes, or papers:
Call independent
k_y/UQ/ensemble batching the production-ready parallelization path when the serial identity gate is current.For runtime scan TOMLs, use
[parallel] strategy = "batch"withaxis = "ky"only for independentk_yscan orchestration.Call whole-state nonlinear sharding a diagnostic correctness/profiler gate, not production nonlinear parallelism unless the exact workload has passed its identity and profiler promotion gates.
Call the electrostatic two-species linear route production-routed and identity-gated, but do not claim speedup until its matched workload profile passes. Other velocity-space
shard_mapwork remains communication-gated and opt-in.Call the mixed species–Hermite streaming backend scoped and identity-gated for periodic Euler/RK2 integration. Quote speedup only for its exact tracked four-logical-CPU workload.
Do not claim nonlinear speedup from sharding, velocity decomposition, spectral toggles, or linear-slice profiles without passing identity gates and fresh profiler artifacts for the exact workload, backend, device count, software stack, and identity tolerance being claimed.
Keep speedup plots separate from identity gates: identity establishes correctness; profiler artifacts establish only the scoped timing claim they measure.
Large-run scaling acceptance checklist
A CPU/GPU strong-scaling result is release-ready only when the tracked artifacts satisfy all of the following:
the combined
*_largeJSON/CSV/PNG/PDF files point back to split CPU and GPU source artifacts for the same workload family;every split artifact records the actual problem size, backend, requested device counts, warmup/repeat policy, and positive per-worker or per-profile timing samples;
every row has
identity_gate_pass = trueand compares against the one-worker or one-device serial reference for the observable being claimed;nonlinear whole-state sharding rows embed the per-device profiler/profile payload, including trace-request status, serial timing stats, sharded timing stats, selected axis, and final-state error metrics;
any speedup wording names the exact backend, device count, workload, grid, software stack, identity tolerance, and artifact files that produced it.
If any item is missing, the result can be kept as local engineering evidence only. In particular, whole-state nonlinear sharding remains not a production nonlinear speedup claim, even when the embedded profile reports a positive engineering timing ratio. Promoting that lane requires fresh profiler artifacts for the exact workload plus full nonlinear identity, conservation, field-solve, FFT/bracket communication, and transport-window gates.
Fast artifact contract check
Before editing scaling docs or manifests, run the checked-in artifact contract:
python tools/release/check_parallel_scaling_artifacts.py
This command does not rerun large profiles and does not enforce any minimum
speedup. It validates that the tracked JSON/CSV/PNG/PDF sidecars exist, the
parallel_scaling manifest lists them, split CPU/GPU source artifacts are
attached where required, numerical identity gates pass, error fields are finite,
and timing/profiler payloads are positive and scoped to their documented claim.
Release artifact policy
The release-gated parallelization artifacts are grouped by what they are allowed to support:
Artifact family |
Primary files |
Claim allowed |
Claim not allowed |
|---|---|---|---|
Independent |
|
Production parallelization for independent linear scans when
|
Nonlinear domain decomposition or nonlinear transport speedup. |
Quasilinear/UQ ensembles |
|
Production batching for independent reduced-feature and UQ workloads. |
Promoted absolute nonlinear heat-flux prediction. |
Whole-state nonlinear sharding |
|
Correctness and profiler-direction evidence for the current |
Production nonlinear multi-GPU speedup. |
Prototype nonlinear state-domain gate |
|
Fail-closed serial-vs-halo-decomposed identity evidence for one bounded local stencil, including the embedded transport-window proxy traces. |
Distributed FFT, field-solve, production conservation, transport-runtime, or speedup claims. |
Prototype nonlinear spectral communication gate |
|
Fail-closed split/reassemble identity evidence for FFT round trip, pseudo-spectral bracket, and spectral field-solve layout. |
Runtime distributed FFT routing, nonlinear conservation, transport-window, or speedup claims. |
Velocity-space linear slices |
|
Bounded engineering evidence for opt-in electrostatic linear RHS slices. |
Electromagnetic, linked-boundary, collision, or nonlinear speedup. |
Both tools/performance_optimization_manifest.toml and
tools/validation_coverage_manifest.toml list these artifacts explicitly.
The tests require the manifests, files, and claim scopes to stay synchronized,
so deleting or silently reinterpreting a scaling artifact fails the fast
parallelization gate.