Examples
The examples directory is organized around two layers:
case-backed runtime drivers that map directly onto the tracked runtime TOMLs,
focused demos and benchmark helpers for theory, operators, and scan workflows.
Config-backed runtime cases
These scripts are the closest match to the production benchmark workflows. They load the checked-in runtime TOMLs and expose only the most useful runtime overrides at the command line.
Tokamak cases
python examples/linear/axisymmetric/cyclone_runtime_linear.py
python examples/nonlinear/axisymmetric/cyclone_runtime_nonlinear.py --steps 200
python examples/linear/axisymmetric/etg_runtime_linear.py
python examples/linear/axisymmetric/kaw_runtime_linear.py
python examples/linear/axisymmetric/kbm_runtime_linear.py
python examples/nonlinear/axisymmetric/kbm_runtime_nonlinear.py --steps 200
python examples/nonlinear/axisymmetric/miller_nonlinear_runtime.py --steps 200
VMEC-backed tokamak and stellarator cases
pip install vmec-jax
cd examples/vmec
./generate_wouts.sh
cd ../..
gkx run --config examples/linear/axisymmetric/runtime_circular_vmec_linear.toml
gkx run --config examples/nonlinear/axisymmetric/runtime_circular_vmec_nonlinear.toml
gkx run --config examples/linear/non-axisymmetric/runtime_hsx_linear_quasilinear.toml
gkx run --config examples/linear/non-axisymmetric/runtime_w7x_linear_quasilinear_vmec.toml
python examples/nonlinear/non-axisymmetric/w7x_nonlinear_vmec_geometry.py --steps 200
python examples/nonlinear/non-axisymmetric/hsx_nonlinear_vmec_geometry.py --steps 200
For the VMEC-backed stellarator examples, omit --steps when you want the
default adaptive horizon. Set --steps only when you intentionally want a
short profiling or diagnostic window. For longer W7-X nonlinear runs, keep
adaptive timesteps enabled (the default for the examples) or reduce dt if
you need a fixed-step stability study.
The bundled VMEC decks are self-contained examples. Exact HSX or W7-X
validation should use the same TOMLs with --vmec-file pointing to the
machine-specific benchmark WOUT. If you only need one local WOUT, run
vmex input.NAME in examples/vmec instead of the full
generate_wouts.sh helper.
The shipped nonlinear stellarator runtime TOMLs now also emit artifact bundles
under tools_out/ by default:
tools_out/w7x_nonlinear_vmec_runtime.diagnostics.csvtools_out/hsx_nonlinear_vmec_runtime.diagnostics.csvtools_out/w7x_nonlinear_imported_runtime.diagnostics.csv
Those diagnostics and their matching *.summary.json files are the intended
inputs for the parity helpers under tools/.
The direct Python runtime wrappers now route through the same artifact-aware
nonlinear path as the executable, so long adaptive runs update that bundle as each
chunk completes.
Runtime TOML entry points
When you want the full config surface instead of the thin case wrappers, use the executable or the generic example drivers directly. These runtime utilities are best treated as solver-smoke and exploration entry points; the benchmark examples remain the audited parity surface for ETG and the other validation lanes:
python examples/utilities/runtime_from_toml.py --config examples/linear/axisymmetric/cyclone.toml
python examples/utilities/runtime_from_toml.py --config examples/linear/axisymmetric/runtime_etg.toml
python benchmarks/etg_linear_benchmark.py --outdir tools_out/etg
python benchmarks/kbm_linear_comparison.py --output tools_out/kbm_linear_comparison.png
gkx run-runtime-linear \
--config examples/linear/axisymmetric/runtime_cyclone_quasilinear.toml \
--out tools_out/cyclone_quasilinear
gkx run-runtime-linear \
--config examples/linear/non-axisymmetric/runtime_w7x_linear_imported_geometry.toml
gkx examples/linear/axisymmetric/cyclone.toml
runtime_kbm.toml is retained as the canonical operator input for controlled
comparison studies. Its experimental shift-invert path fails closed while the
full-resolution physical residual exceeds the documented acceptance gate; use
the reviewed comparison driver above for the promoted KBM result.
For a bounded runtime-configured independent k_y scan that uses
[parallel] strategy = "batch" without changing the single-k_y solver
layout, run:
python examples/parallelization/independent_ky_runtime_batch_scan.py
The companion
examples/parallelization/runtime_batch_ky_scan.toml selects two thread
workers through [parallel].num_devices. The runtime still dispatches normal
single-k_y solver calls and gathers results in input order; it does not opt
into the combined-k_y solver path.
Scaling utilities
For production parallelization of independent scans and UQ ensembles, prefer the package helpers:
import jax.numpy as jnp
import gkx as sgk
ky = jnp.asarray([0.1, 0.2, 0.3, 0.4])
chunks = sgk.ky_scan_batches(ky, n_batches=2)
values = sgk.batch_map(
lambda x: {"gamma": x, "ql_weight": x**2},
ky,
batch_size=2,
)
For file-backed calibration and uncertainty workflows that are independent but
not JAX-array vmap workloads, use sgk.independent_map:
rows = sgk.independent_map(
lambda case: {"case": case, "score": len(case)},
["cyclone", "hsx", "w7x"],
workers=2,
)
These helpers preserve serial ordering and fall back to a one-device vmap
path on laptops. Multi-device runs should still be checked against the serial
result before publication speedups are claimed.
Autodiff validation reports also accept workers for thread-parallel
central finite-difference columns. The development-only reduced diagnostic
comparison exposes the same pattern:
JAX_ENABLE_X64=1 python examples/theory_and_demos/reduced_stellarator_itg/compare_stellarator_itg_optimizations.py \
--workers 3 \
--finite-difference-workers 2
The generated JSON records both worker counts and keeps the acceptance criterion as numerical identity with the serial report.
For a solver-backed identity gate, run the Cyclone k_y-batch scan artifact:
python tools/artifacts/generate_parallel_identity_gate.py ky-scan
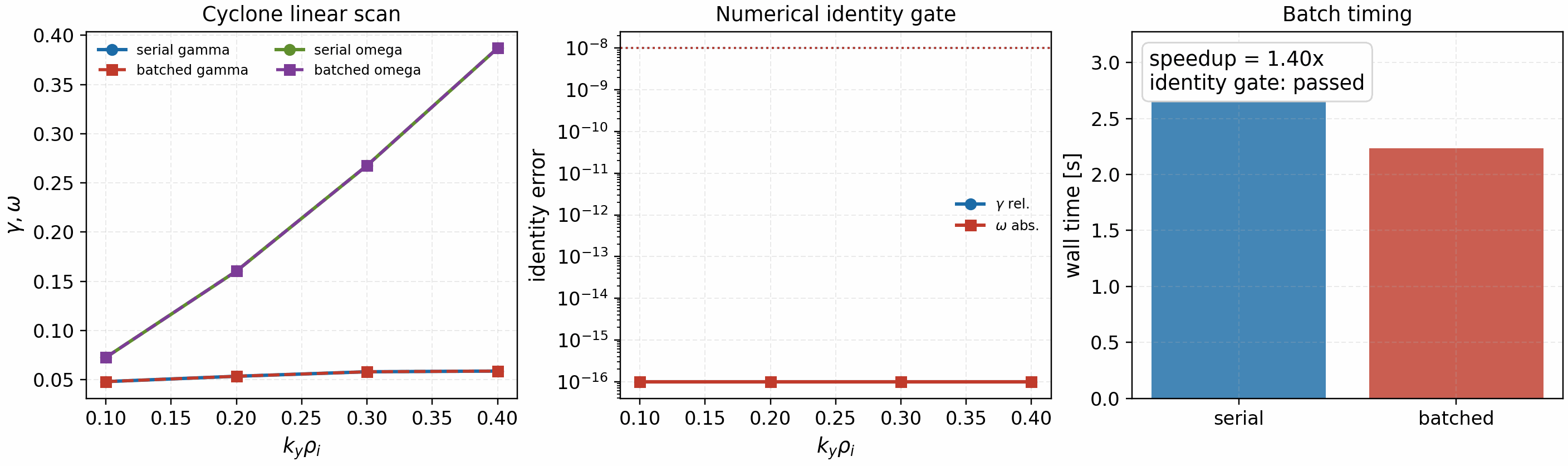
Real Cyclone linear solver comparison between serial and fixed-shape
k_y-batched scans. The figure verifies that gamma and omega
are identical while reporting the observed batch speedup separately.
For a logical-CPU API gate that exercises RuntimeParallelConfig and pytree
outputs, run:
python tools/artifacts/generate_parallel_identity_gate.py logical-cpu --logical-devices 2
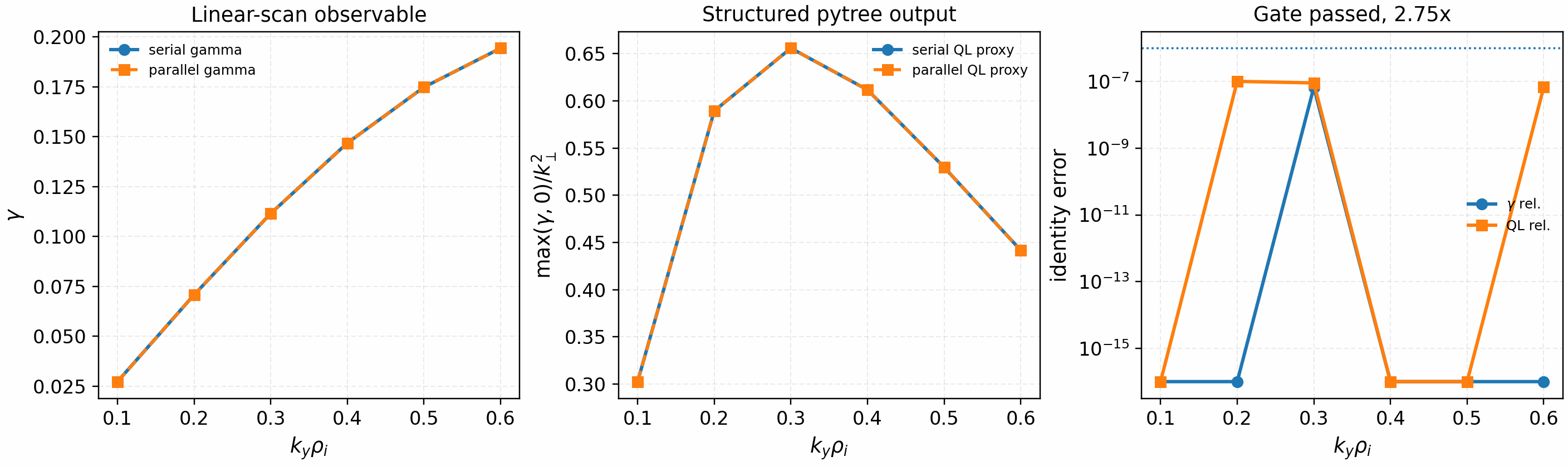
Independent-scan interface gate for structured outputs. This validates the parallel API used by UQ and sensitivity ensembles; it is not a nonlinear performance claim.
The first lower-level communication gate for velocity-space decomposition is the Hermite ghost exchange:
python tools/artifacts/generate_velocity_parallel_gates.py hermite-exchange --logical-devices 2
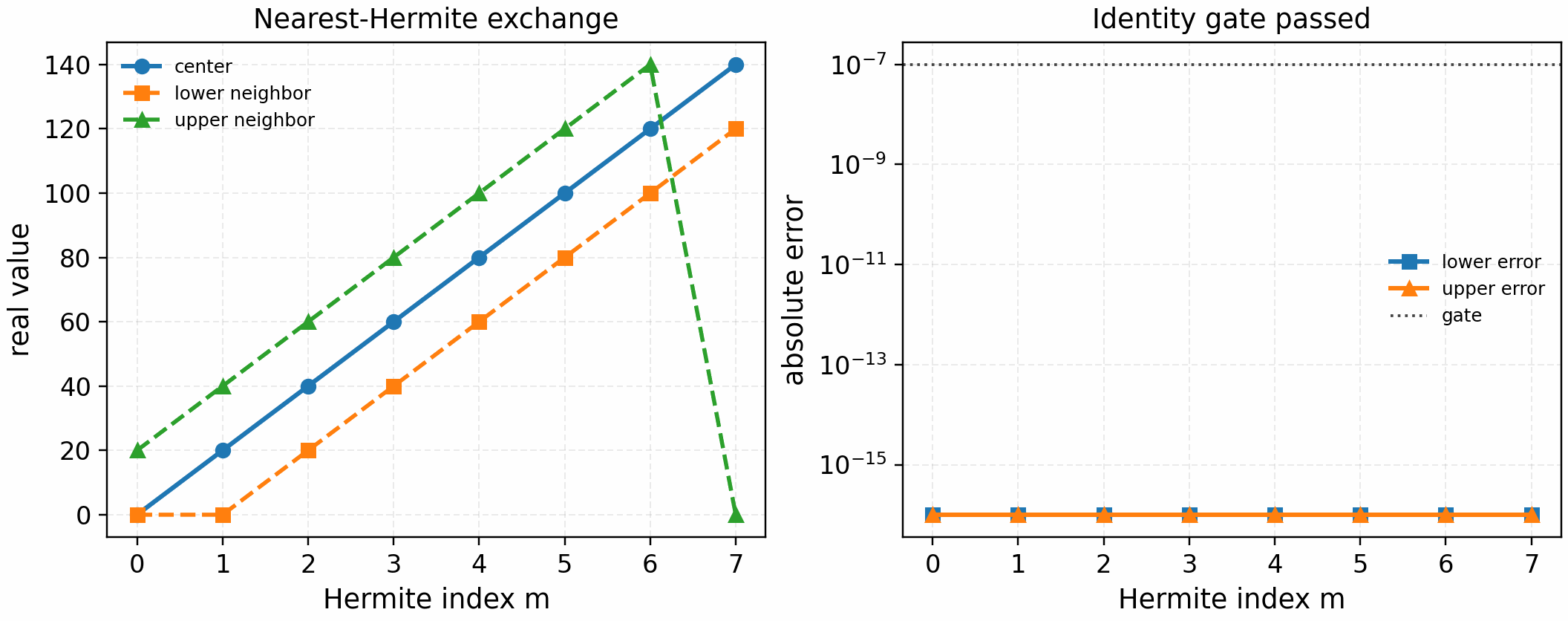
shard_map nearest-neighbor exchange for Hermite moments. This validates
the communication primitive that a future nonlinear velocity-space sharding
path needs before field reductions and full-RHS identity gates are added.
The paired field-reduction gate is:
python tools/artifacts/generate_velocity_parallel_gates.py field-reduce --logical-devices 2
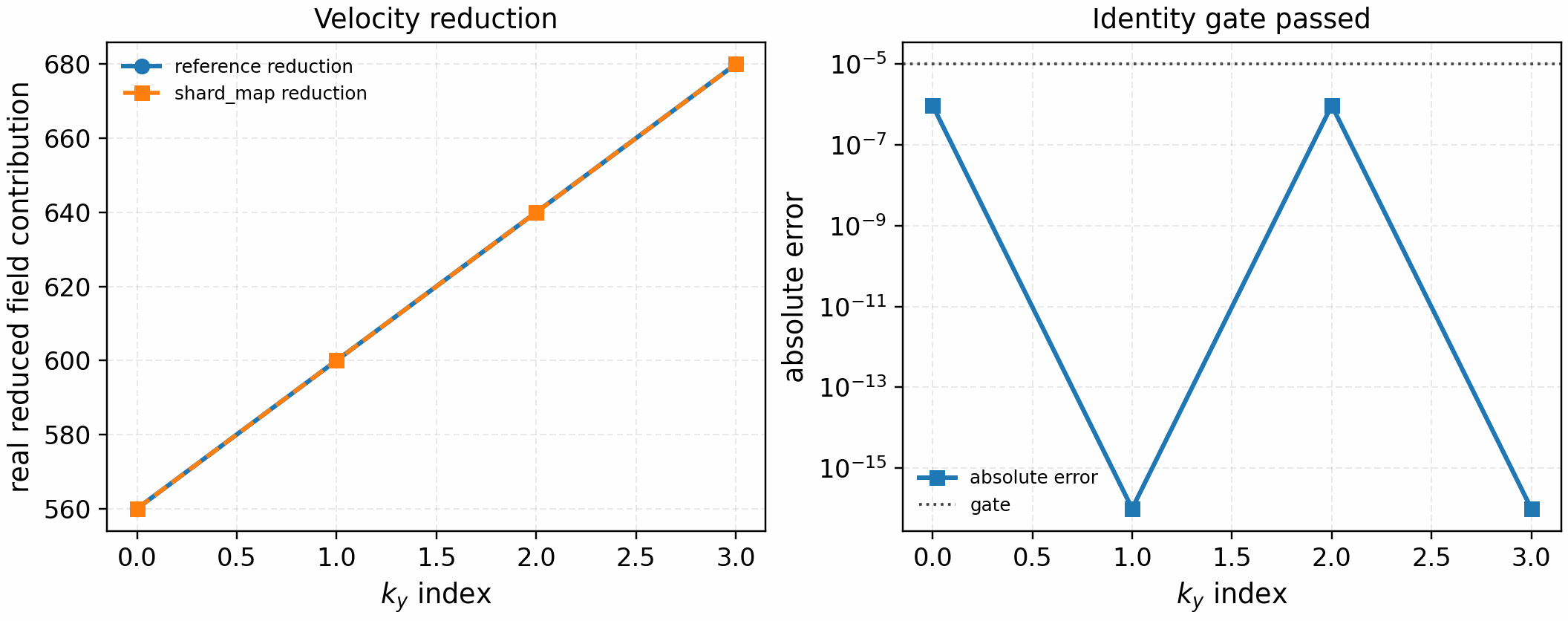
shard_map reduction/broadcast over a Hermite mesh. This establishes the
field-solve communication primitive before streaming-ladder and nonlinear
RHS identity gates are attempted.
The first production-field-solve reduction gate is:
python tools/artifacts/generate_electrostatic_parallel_gates.py field-reduce --logical-devices 2
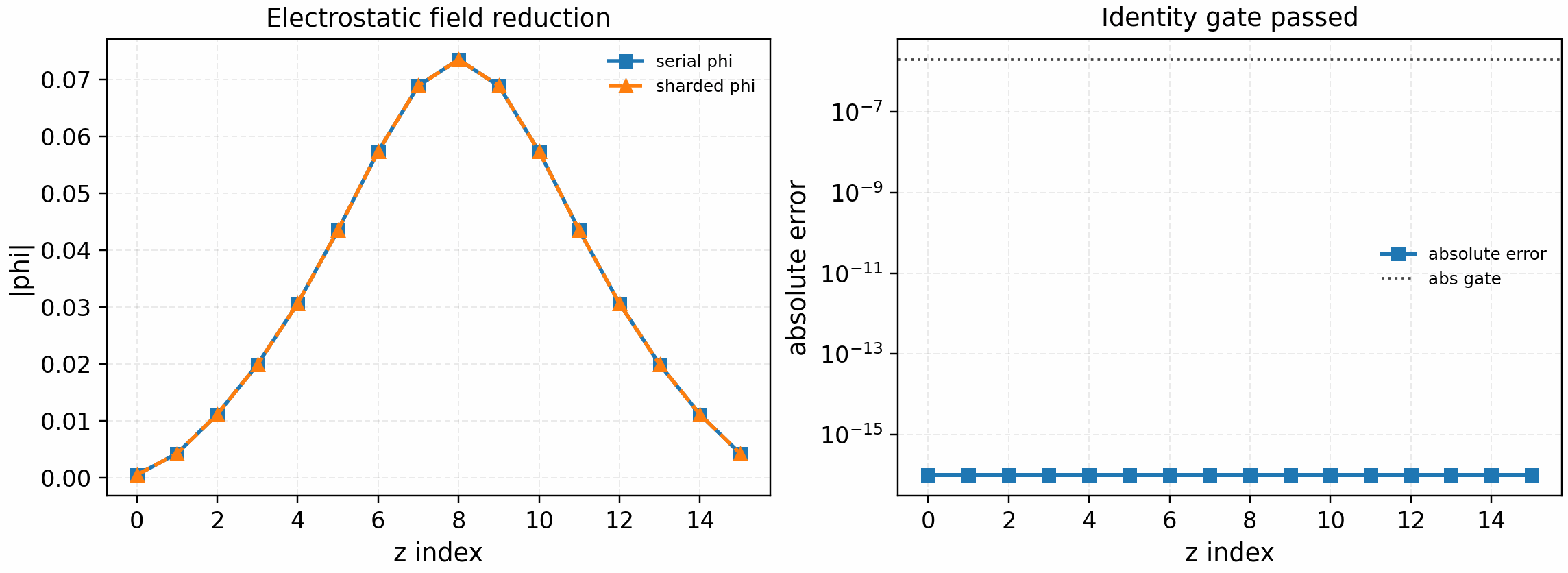
Hermite-sharded m=0 density reduction for the electrostatic
quasineutrality solve, compared against the production field solve.
The Hermite streaming-ladder coefficient gate is:
python tools/artifacts/generate_velocity_parallel_gates.py hermite-ladder --logical-devices 2
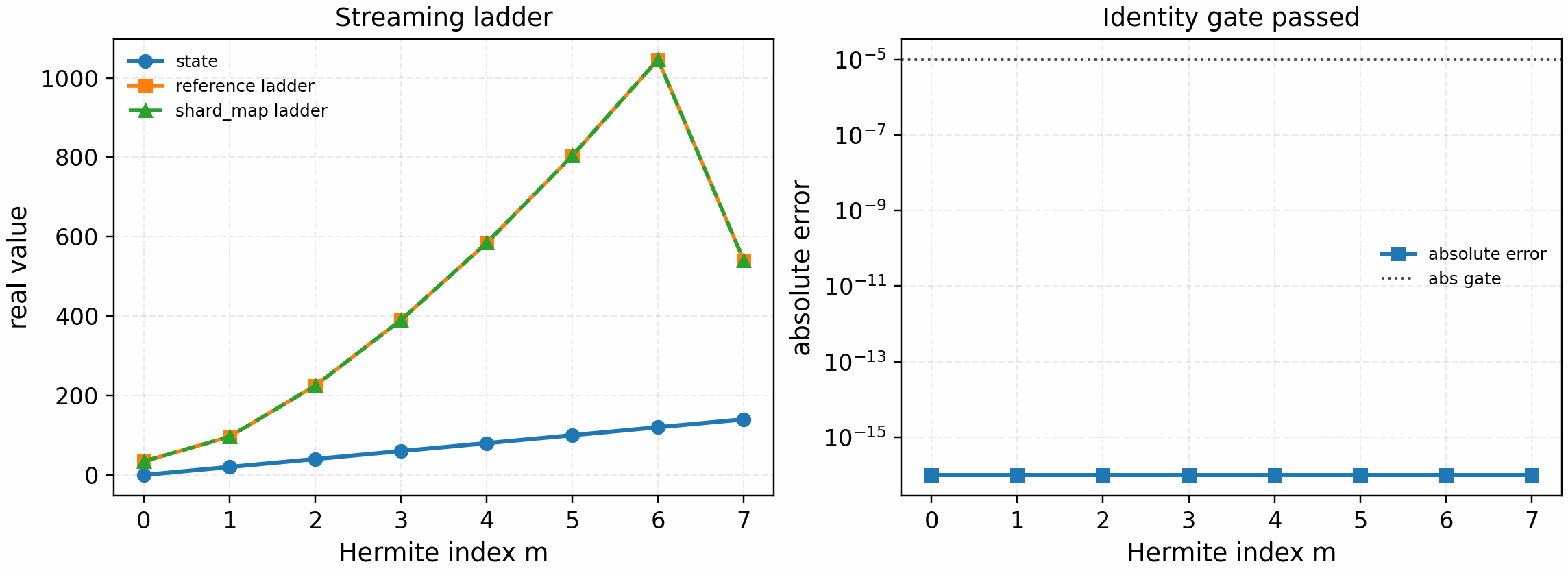
shard_map Hermite exchange plus the sqrt(m+1) / sqrt(m)
streaming-ladder coefficients. This is still a communication/coefficient
gate; full linear streaming also needs the parallel derivative identity
gate before production runtime wiring.
The first electrostatic drift-slice gate is:
python tools/artifacts/generate_electrostatic_parallel_gates.py drift --logical-devices 2
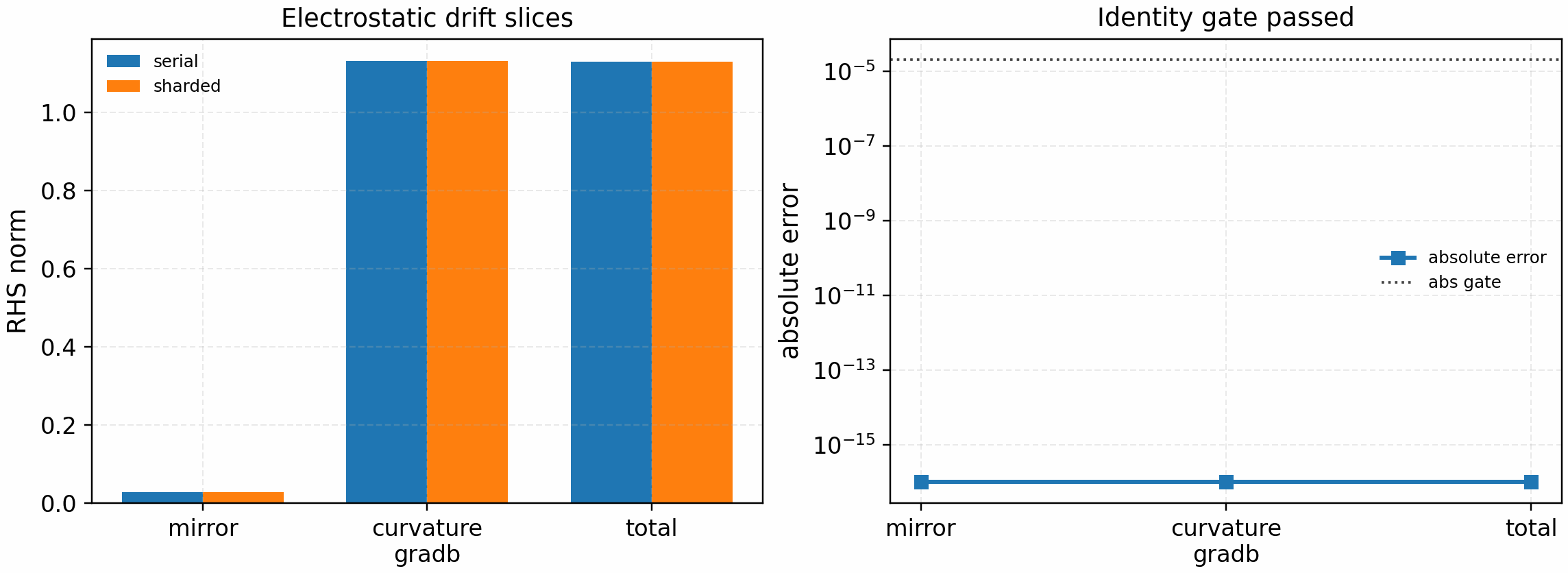
Hermite-sharded mirror and curvature/grad-B drift slices, including offset-1 and offset-2 Hermite exchanges, compared against the production linear RHS with only those terms enabled.
The matching electrostatic diamagnetic-drive gate is:
python tools/artifacts/generate_electrostatic_parallel_gates.py diamagnetic --logical-devices 2
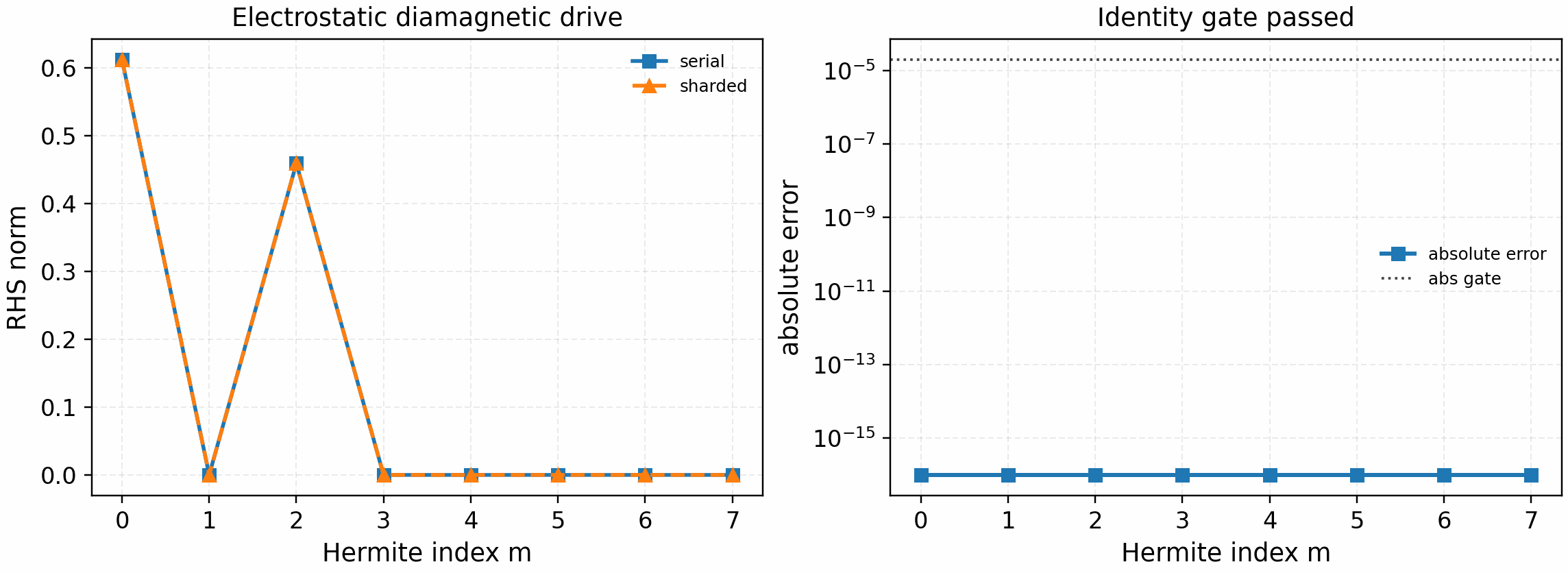
Hermite-sharded electrostatic diamagnetic drive. The sharded route first
uses the electrostatic field-reduction gate, then applies the local
m=0 and m=2 drive masks on each Hermite shard. This closes the
diamagnetic slice for the opt-in electrostatic linear-slices backend.
The periodic streaming microkernel gate adds that field-line derivative:
python tools/artifacts/generate_velocity_parallel_gates.py periodic-streaming --logical-devices 2
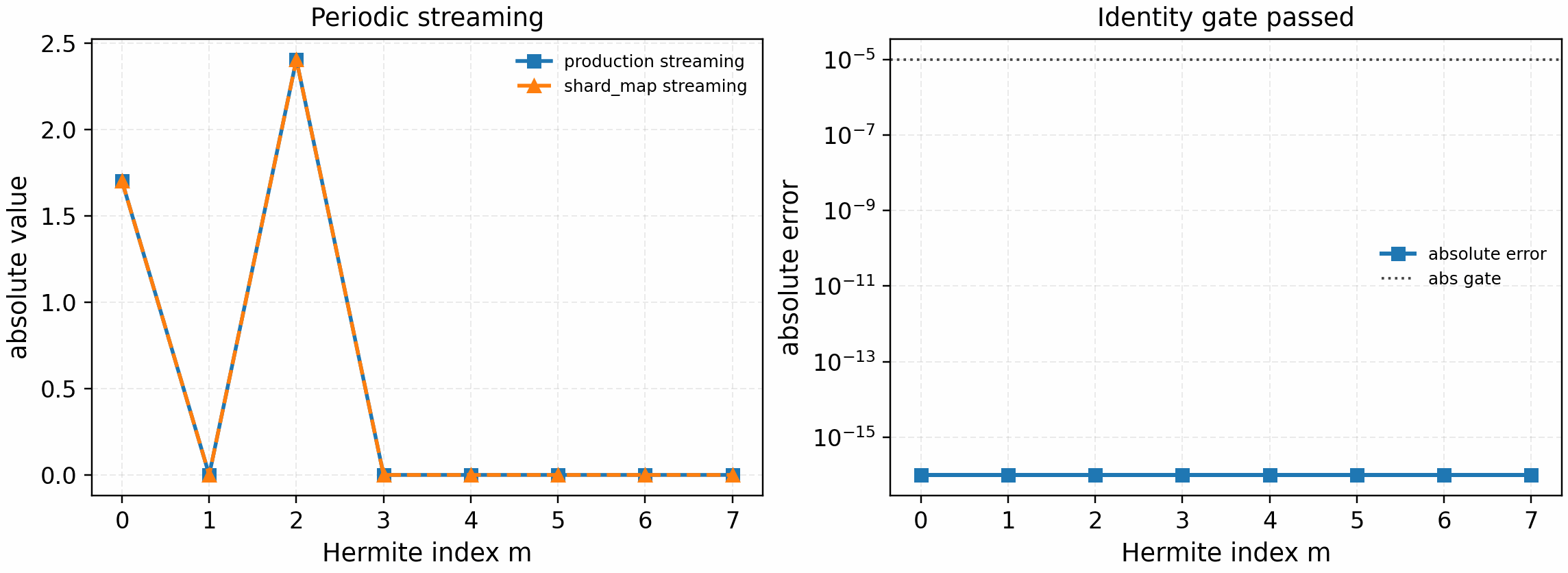
Periodic spectral parallel derivative plus Hermite streaming ladder through
the shard_map path, compared directly against the production streaming
operator.
The next gate places that same sharded streaming kernel under the production linear-RHS call graph with every non-streaming contribution disabled:
python tools/artifacts/generate_linear_rhs_parallel_gates.py streaming --logical-devices 2
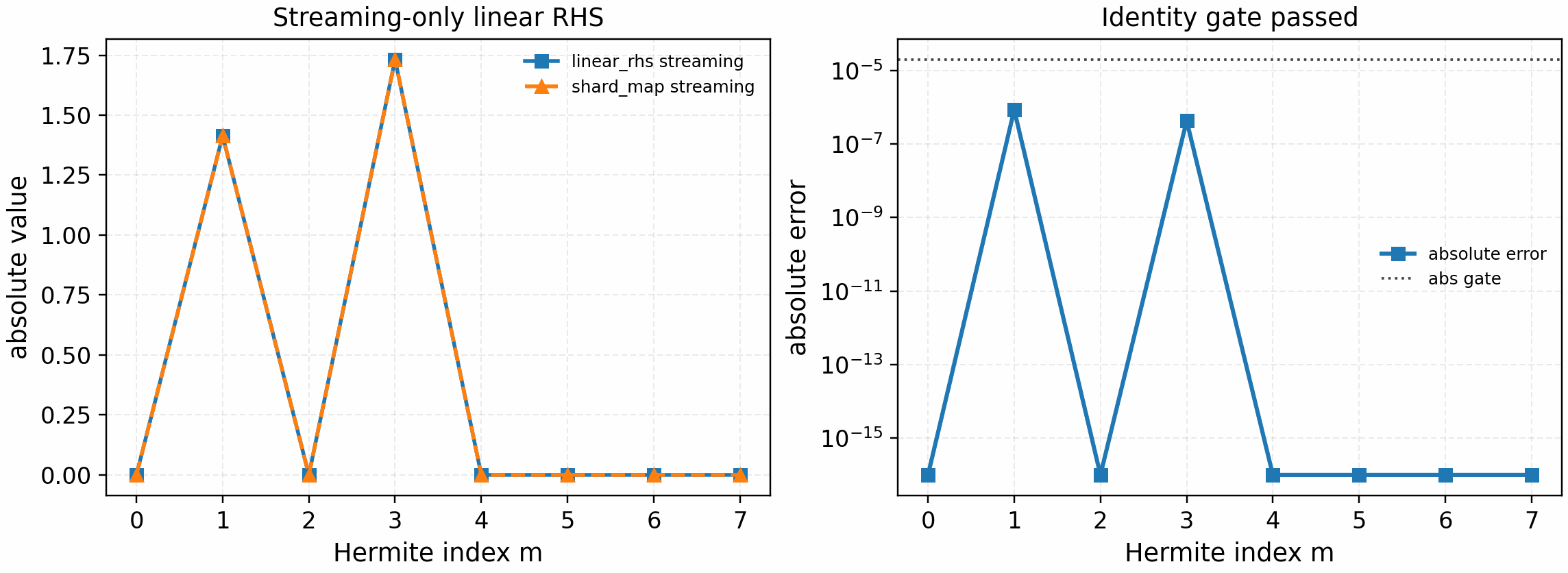
Streaming-only linear_rhs_cached comparison against the velocity-sharded
periodic streaming path. This closes the first full-RHS call-graph identity
gate for the streaming term only; it is not yet a full linear scan or
nonlinear speedup claim.
With a nonzero electrostatic response, use:
python tools/artifacts/generate_linear_rhs_parallel_gates.py streaming-electrostatic --logical-devices 2
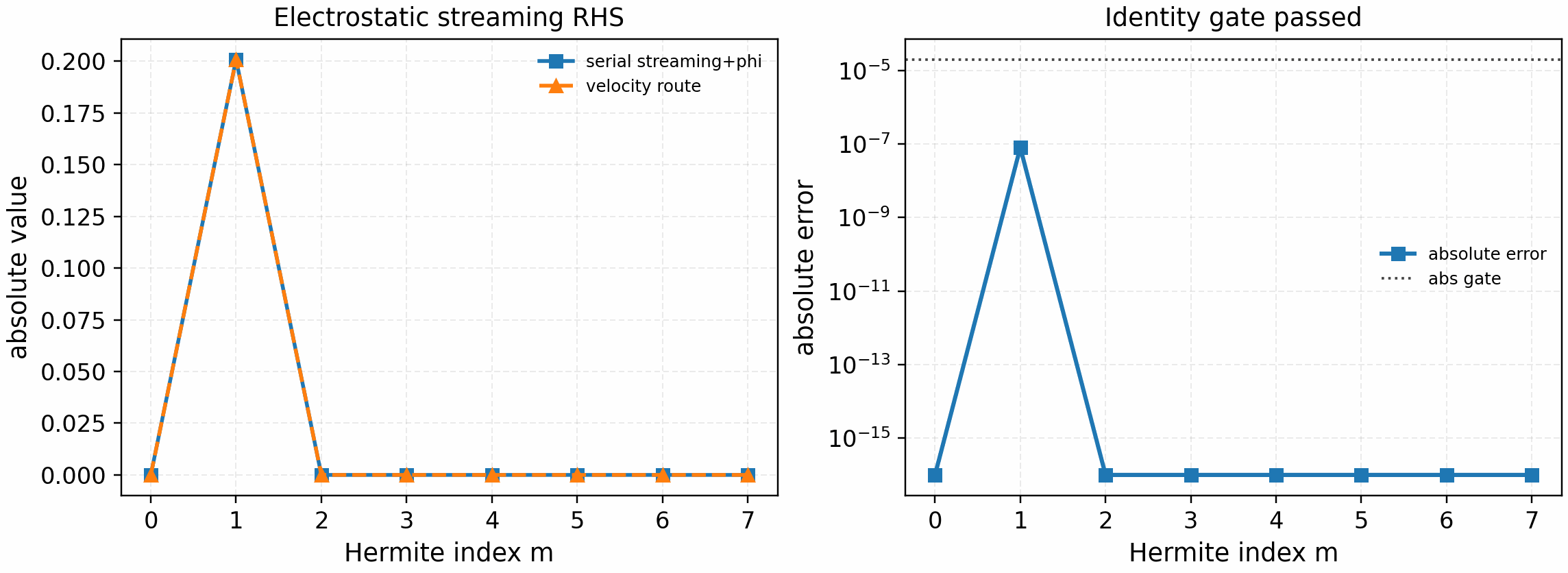
Streaming plus electrostatic phi call-graph comparison. The field solve
uses the Hermite-sharded electrostatic reduction gate; this validates the
next velocity-sharded streaming slice before drift, diamagnetic-drive, and
nonlinear terms are introduced.
For the composed electrostatic linear-slices backend, use:
python tools/artifacts/generate_linear_rhs_parallel_gates.py electrostatic-slices --logical-devices 2
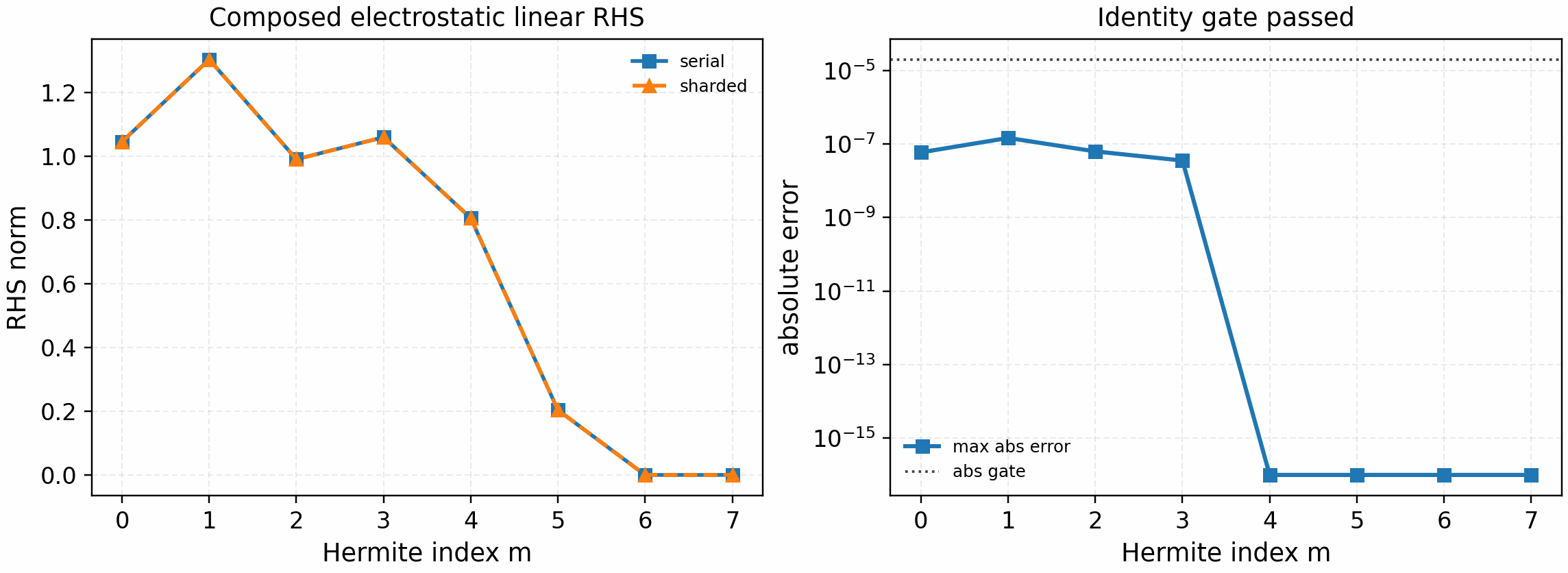
Full opt-in electrostatic linear-slices call-graph comparison for streaming, mirror, curvature, grad-B, and diamagnetic drive. This is an opt-in electrostatic linear-RHS identity artifact for the single-species periodic electrostatic RHS path; collisions, linked boundaries, electromagnetic terms, and nonlinear brackets remain separate gates.
Use the strong-scaling sweep helper to collect parallelization timings for the distributed linear RK2 loop:
python examples/utilities/strong_scaling_sweep.py \
--ny 128 --nz 256 --nl 8 --nm 8 --steps 120 \
--devices 1,2,4,8 \
--backend cpu_parallel_large \
--out tools_out/strong_scaling_cpu.csv
On multi-GPU systems, point --devices at the available accelerators and
update --backend accordingly (for example cuda_parallel_large). The
backend labels are just sweep names for the output table; they do not change
the runtime physics or solver path.
For the current opt-in Hermite-sharded electrostatic linear RHS path, use the engineering sweep helper:
python tools/profiling/profile_linear_rhs_parallel_slices.py sweep \
--platform cpu --devices 1,2,4,8 --nms 64,128 \
--nl 4 --ny 32 --nz 128 --rtol 1e-5
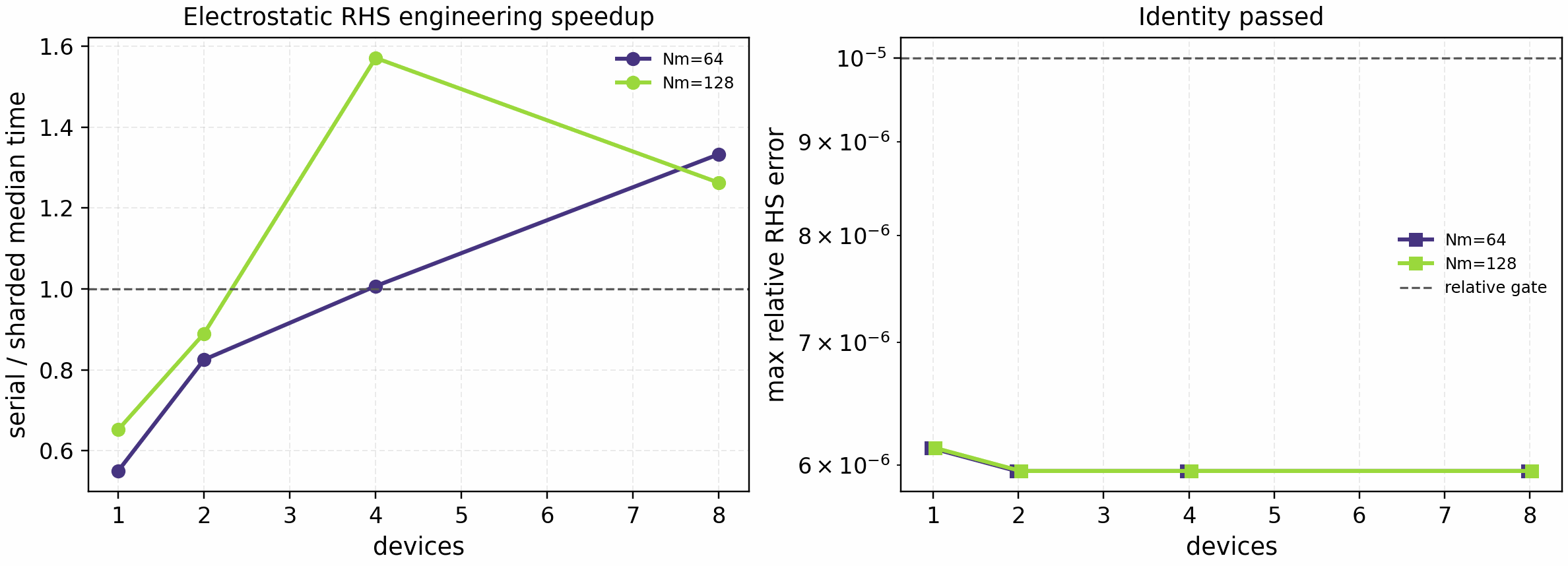
Device-count and Hermite-resolution sweep for the opt-in electrostatic linear-slices backend. The right panel is the identity gate; the left panel is engineering timing only and should not be promoted as a nonlinear or publication speedup claim.
Plotting outputs
To visualize nonlinear diagnostic histories from *.out.nc files:
python examples/utilities/plot_runtime_outputs.py tools_out/cyclone_release.out.nc \
--out tools_out/cyclone_release_diagnostics.png
Geometry examples
VMEC and Miller geometry usage examples are documented in Geometry.
Nonlinear restart and continuation
The tracked nonlinear runtime path supports a NetCDF out/big/restart
bundle together with continuation from the saved restart state.
One-shot nonlinear bundle write:
gkx run-runtime-nonlinear \
--config examples/nonlinear/axisymmetric/runtime_cyclone_nonlinear.toml \
--steps 200 \
--out tools_out/cyclone_release.out.nc
For the short Cyclone comparison replay (t_max = 5, no collisions), use
examples/nonlinear/axisymmetric/runtime_cyclone_nonlinear_short.toml.
That file pins the short-run dissipation contract explicitly
(p_hyper = 2, damp_ends_amp = 0) instead of relying on the longer
production defaults.
Restart-aware TOML snippet:
[time]
nstep_restart = 100
[output]
path = "tools_out/cyclone_release.out.nc"
restart_if_exists = true
save_for_restart = true
append_on_restart = true
restart_with_perturb = false
With that configuration, rerunning the same nonlinear command resumes from
tools_out/cyclone_release.restart.nc when it already exists and appends the
continued history to tools_out/cyclone_release.out.nc. This is the
recommended user-facing workflow for long nonlinear turbulence jobs.
Geometry generation workflows
The runtime geometry path generates imported geometry files from VMEC or Miller inputs. VMEC uses the documented optional geometry bridge; Miller uses the in-package backend and needs no external helper:
cd examples/vmec
vmex input.NuhrenbergZille_1988_QHS
cd ../..
export GKX_BOOZ_XFORM_JAX_PATH=/absolute/or/relative/booz_xform_jax
gkx geometry vmec \
--config examples/nonlinear/non-axisymmetric/runtime_hsx_nonlinear_vmec_geometry.toml
gkx geometry miller \
--config examples/nonlinear/axisymmetric/runtime_cyclone_nonlinear_miller.toml
Benchmark and scan helpers
These scripts produce the scan-level plots and tables used in the benchmark discussion:
python benchmarks/cyclone_linear_benchmark.py
python benchmarks/etg_linear_benchmark.py
python benchmarks/kbm_linear_comparison.py
python benchmarks/kinetic_linear_benchmark.py
python benchmarks/tem_linear_benchmark.py
kbm_linear_comparison.py plots the reviewed fixed-beta ky table. The
matched rerun and branch-continuity analysis live in
tools/comparison/compare_gx_kbm.py.
The kinetic-electron script loads
examples/linear/axisymmetric/runtime_kinetic_electron.toml. The same input
can be run directly with
gkx examples/linear/axisymmetric/runtime_kinetic_electron.toml.
The TEM script loads examples/linear/axisymmetric/runtime_tem.toml; users
can run the same single-mode case directly with
gkx examples/linear/axisymmetric/runtime_tem.toml.
Foundational demos
These smaller examples are useful for understanding the numerical building blocks without running a full benchmark case:
python benchmarks/basis_orthonormality.py
python examples/theory_and_demos/cyclone_geometry.py
python examples/theory_and_demos/autodiff_inverse_growth.py
python examples/theory_and_demos/autodiff_inverse_twomode.py
python examples/theory_and_demos/diffrax_linear_demo.py
python examples/theory_and_demos/example.py
python examples/theory_and_demos/gradB_coupling_hl_1d.py
python examples/theory_and_demos/linear_rhs_demo.py
python examples/theory_and_demos/two_stream_hermite_1d.py
Differentiable optimization examples
The public optimization examples are actual VMEC-JAX QA stellarator workflows with one GKX transport tuple appended to the VMEC-JAX objective list:
python examples/optimization/QA_optimization_linear_ITG.py
python examples/optimization/QA_optimization_quasilinear_ITG.py
python examples/optimization/QA_optimization_nonlinear_ITG.py
The three QA_optimization_*_ITG.py scripts intentionally mirror upstream
vmex/examples/optimization/QA_optimization.py on the current
VmecInput/opt.least_squares API. They preserve its A=6 and mean-
iota=0.42 targets and add only one GKX objective tuple. Keep the
transport weight small until solved-equilibrium aspect, iota, and
quasisymmetry gates pass. They are deliberately edited through top-level
constants, not command-line arguments.
The linear-growth script uses VMEC-JAX’s implicit Jacobian. The quasilinear and reduced nonlinear-window scripts use finite-difference outer Jacobians because their dominant-eigenvector weights do not yet have the required JAX derivative. None of these optimizer residuals is a saturated heat-flux claim.
Reduced synthetic scripts are kept outside examples/optimization as
development diagnostics only:
python examples/theory_and_demos/reduced_stellarator_itg/stellarator_itg_growth_optimization.py
python examples/theory_and_demos/reduced_stellarator_itg/stellarator_itg_quasilinear_flux_optimization.py
python examples/theory_and_demos/reduced_stellarator_itg/stellarator_itg_nonlinear_heat_flux_optimization.py
python examples/theory_and_demos/reduced_stellarator_itg/compare_stellarator_itg_optimizations.py
python examples/theory_and_demos/reduced_stellarator_itg/stellarator_itg_portfolio_gate.py --finite-difference-workers 2
The portfolio gate writes JSON/PNG/PDF artifacts and checks scalar plus
row-wise AD/finite-difference agreement for the same surface/alpha/k_y
reduction that will be used by the production VMEC/Boozer objective rows. Its
default table covers three surfaces, two field-line alpha values, and
three k_y values with growth and quasilinear-flux columns. This is a
reduced/model-development gate; it does not claim optimized nonlinear heat
flux or calibrated saturated transport. Treat the JSON sidecar as the audit
source; the PNG/PDF summarize the same sidecar for docs and review.
The production bridge now exposes the same portfolio layout for real
vmex -> booz_xform_jax -> GKX rows:
stellarator_itg_vmec_boozer_sample_objective_table_from_state returns a
(surface, alpha, ky, objective) table and
stellarator_itg_vmec_boozer_portfolio_objective_from_state reduces it with
the same weights as the cheap gate. Promotion still requires held-out
surface/field-line artifacts and matched baseline/optimized long
post-transient nonlinear windows, not startup traces or reduced-window
estimators.
The autodiff demos write summary JSON plus R/L_Ti and R/L_n sweep CSVs in the chosen output directory alongside the publication-ready plots. The single-mode figure is a local inverse/sensitivity example; the two-mode figure is the release-grade parameter-recovery validation.
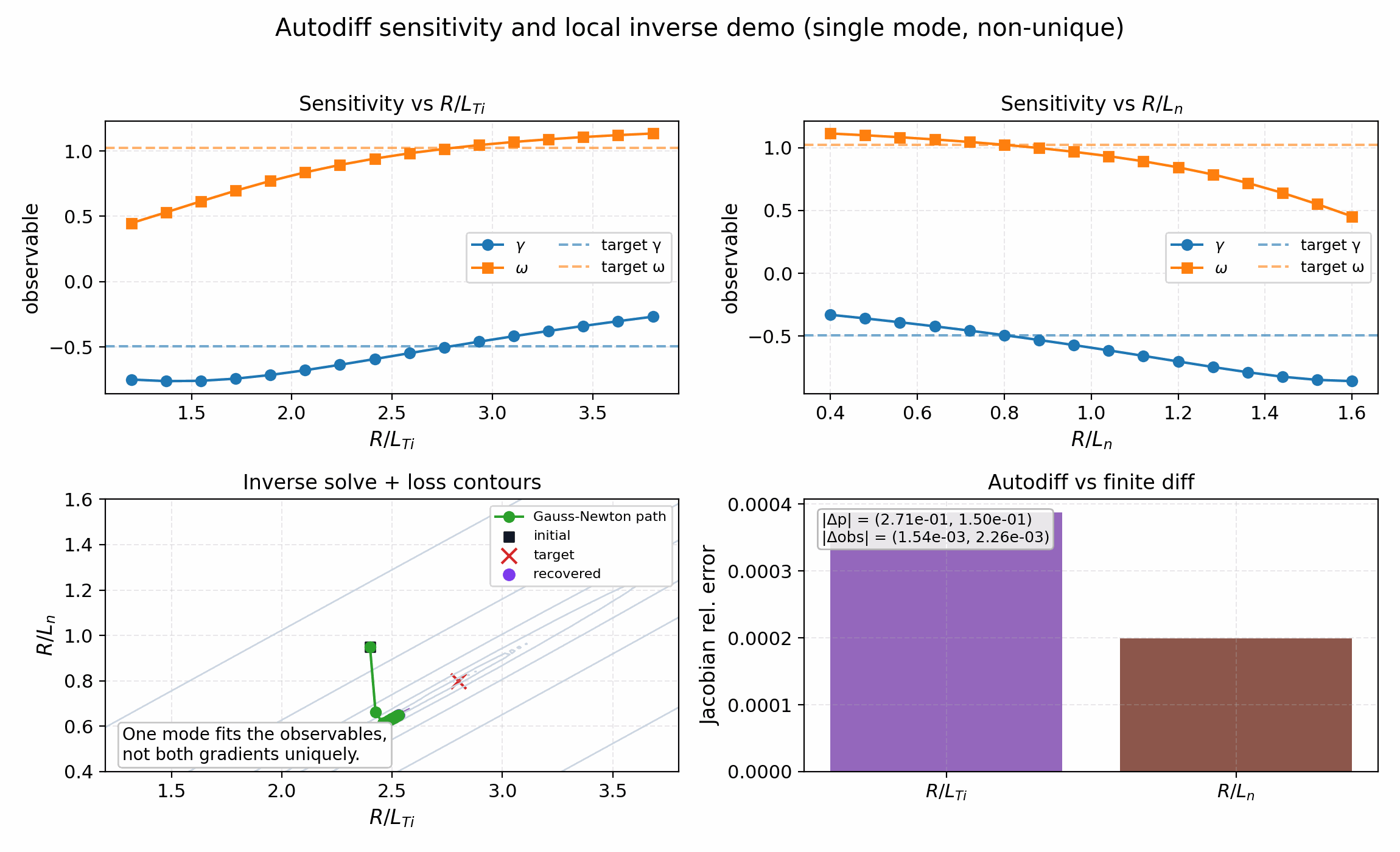
Single-mode inverse/sensitivity demo. The goal is to verify the autodiff Jacobian and show what one measured mode constrains locally; the expected outcome is small observable and derivative error, not unique recovery of both gradients. The shipped result matches that expectation: (gamma, omega) are reproduced closely while the recovered (R/L_Ti, R/L_n) remains offset because the one-mode inverse is not globally identifiable.
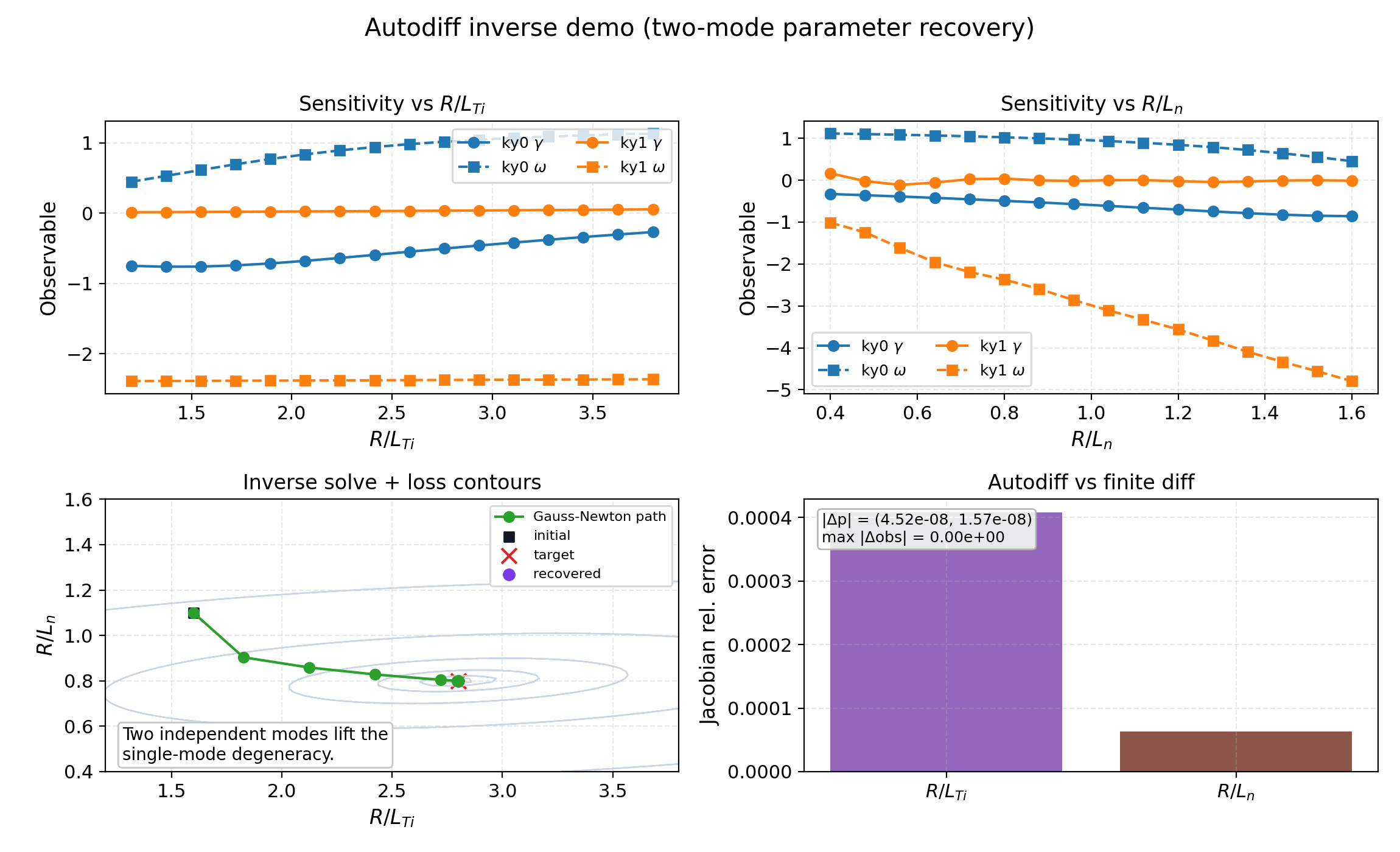
Two-mode inverse validation. The goal is to recover the planted gradients from two independent mode observables and verify that the autodiff Jacobian stays consistent with finite differences. The shipped result reaches the target to numerical precision and is the reviewer-facing parameter-recovery validation.
Secondary slab workflow
python -m gkx.cli run-runtime-linear \
--config benchmarks/runtime_secondary_slab.toml
python benchmarks/secondary_slab_workflow.py
The staged helper runs the linear seed, writes a restart state in the runtime binary layout, and then launches the nonlinear follow-up with the matching restart and fixed-mode controls used in the tracked secondary benchmark.
Full-GK ETG nonlinear pilot
python examples/nonlinear/axisymmetric/etg_runtime_nonlinear.py --steps 200
JAX_ENABLE_X64=1 gkx examples/nonlinear/axisymmetric/runtime_etg_nonlinear.toml --steps 200
This is the full-GK two-species ETG nonlinear pilot lane. The shipped
contract now matches the audited short-window startup path: Lx = 1.25 for the linked ETG box and
gaussian_init = true with init_single = false because GX reads
init_single from its [Expert] section, not from [Initialization].